死屋手记
JVM笔记
1.par new + cms 的GC,如何保证只做ygc,jvm参数如何配置?
答:首先上线系统后,要借助一些工具观察每秒钟会新增多少对象在新生代里,然后多长时间触发一次Minor GC,平均每次Minor GC之后会有多少对象存活,Survivor区是否可以放的下。这里的关键点就是必须让Survivor区放下,而且不能因为动态年龄判定规则直接升入老年代,然后只要Survivor区可以放下,那么下次Minor GC后还是存活这么多对象,依然可以在另外一块Survivor区放下,基本就不会有对象升入老年代。
2.当老年代的可用内存空间小于新生代所有对象的总大小时,无论有没有空间分配担保,最坏的情况都是一次Minor GC + Full GC,那为什么还需要分配担保机制?直接Minor GC,之后再进行那三种判断不就行了,HandlePromotionFail的意义何在?
答:如果没有开启一个检查,此时可能提前Full GC,那么这样就太频繁了,如果经过检查机制,发现不需要Full GC就直接Minor GC;差别在于不需要频繁Full GC。
3.CMS垃圾回收器
CMS在执行一次垃圾回收的过程一共分为4个阶段:
1.初始标记: 这个阶段会让系统的工作线程全部停止,进入“Stop the World”状态,然后标记出来所有GC Roots直接引用的对象。虽说要造成“Stop the World”,但其实影响不大,因为他的速度很快,仅仅标记GC Roots直接引用的那些对象。
2.并发标记: 这个阶段会让系统线程可以随意创建各种对象,继续运行,在运行期间可能会创建新的存活对象,也可能会让部分存活对象失去引用,变成垃圾对象,在这个过程中,垃圾回收线程,会尽可能的对已有的对象进行GC Roots追踪。这个阶段是对老年代所有对象进行GC Roots追踪,是最耗时的,他需要追踪所有对象是否从根源上被GC Roots引用了,但这个最耗时的阶段,是跟系统程序并发运行的,所以其实这个阶段不会对系统运行造成影响
3.重新标记: 因为第二阶段结束后,会有很多存活对象和垃圾对象是之前第二阶段没标记出来的,所以此时进入第三阶段,继续让系统程序停下来,再次进入“Stop the World”阶段,然后重新标记下在第二阶段里新创建的一些对象,还有一些已有对象可能失去引用变成垃圾的情况。这个阶段速度很快的,他其实就是对在第二阶段中被系统程序运行变动过的少数对象进行标记,所以运行速度很快。
4.并发清理: 这个阶段就是让系统程序随意运行,然后他来清理掉之前标记为垃圾的对象即可。这个阶段是很耗时的,因为需要进行对象的清理,但是他和系统程序并发运行的,所以其实也不影响系统程序的执行。
CMS性能分析:第一和第三阶段虽然需要“STW”,但是这两个阶段都是简单的标记,速度非常快,基本上对系统运行响应也不大;第二和第四阶段是最耗时的,但都是和系统程序并发执行的,基本这两个最耗时的阶段对性能影响不大。
Centos7 虚拟机ip配置
###1.查看主机ip地址及网关###
# ifconfig
###2.修改配置###
在虚拟机中找到/etc/sysconfig/network-scripts/ifcfg-enp0s3文件并编辑
TYPE=Ethernet
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INI=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=enp0s3
UUID=xxxxxxx
DEVICE=enp0s3
ONBOOT=yes
IPADDR=192.168.xx.xx (和宿主主机同一网段)
PREFIX=24
GATEWAY=192.168.xx.xx
DNS1=114.114.114.114
DNS2=8.8.8.8
IPV6_PEERDNS=yes
IPV6_PEERROUTES=yes 3.重启服务
# service network restart
查看ip地址命令:# ip add 地下室手记
第一次读陀思妥耶夫斯基,选的第一本是《地下室手记》,很小很薄的一本书,想做为读陀氏的入门。读完后,觉得甚是过瘾,以下简单写写读后感想。
主人公是一个年四十岁的公务员,得到远房亲戚遗留下的一笔遗产时,立刻辞职,蛰居在自己的小角落里。然后以地下室人的身份,以第一人称进行了一系列自身的剖析、诉说、与斗争,大段大段的内心独白,将自己思想的矛盾与精分展现的淋漓尽致。在看书的过程中,时刻看到自己的影子,随时跟着主人公一起精分,歇斯底里的咆哮、狂怒,然后又归于平静。
数据库事务
一、数据库事务的4个特性(ACID)
原子性(Atomic)
表示组成一个事务的多个数据库操作是一个不可分割的原子单元,只有所有的操作执行成功,整个事务才提交。事务中的任务一个数据库操作失败,已经执行的任何操作都必须撤销,让数据库返回到初始状态。一致性(Consistency)
事务操作成功后,数据所处的状态和它的业务规则是一致的,即数据不会被破坏。如从A账户转账100元到B账户,不管操作成功与否,A账户和B账户的存款总额是不变的。隔离性(Isolation)
在并发数据操作时,不同的事务拥有各自的数据空间,它们的操作不会对对方产生干扰。准备说,并非要求做到完全无干扰。数据库规定了多种事务隔离级别,不同的隔离级别对应不同的干扰程序,隔离级别越高,数据一致性越好,但并发性越弱。持久性(Durabiliy)
一旦事务提交成功后,事务中所有的数据操作都必须被持久化到数据库中。即使在提交事务后,数据库马上崩溃,在数据库重启时,也必须保证能够通过某种机制恢复数据。
二、事务的并发问题
脏读
A事务读取了B事务尚未提交的更改数据,B事务可能发生回滚,这时A事务读到的数据根本不存在,发生了脏读。不可重复读
A事务读取了B事务已经提交的更改数据。幻象读
A事务读取B事务提交的新增数据,这时A事务将出现幻象读。 幻象读一般发生在计算统计数据的事务中。第一类丢失更新
A事务撤销时,把已经提交的B事务的更新数据覆盖了。第二类丢失更新
A事务覆盖B事务已经提交的数据,造成B事务所做操作丢失。
注:幻象读和不可重复读是两个容易混淆的概念,前者是指读到了其他已经提交事务的新增数据,而后者是指读到了已经提交事务的更改数据(更改或删除)。为了避免这两种情况,采取的对策是不同的:防止读到更改数据,只需对操作的数据添加行级锁,阻止操作中的数据发生变化;而防止读到新增数据,则往往需要添加表级锁,即将整张表锁定,防止新增数据。
三、数据库锁机制
数据并发会引发很多问题,在一些场合下有些问题是允许的,但在另一些场合下可能是致命的。数据库通过锁机制解决并发访问的问题。按锁定的对象不同,一般可以分为表锁定和行锁定。前者对整张表进行锁定,后者对表中的特定行进行锁定。从并发事务锁定的关系上看,可以分为共享锁定和独占锁定。共享锁定会防止独占锁定,但允许其他的共享锁定;而独占锁定既防止其他的独占锁定,也防止其他的共享锁定。
四、事务隔离级别
尽管数据库为用户提供了锁的DML操作方式,但直接使用锁管理是非常麻烦的,因为数据库为用户提供了自动锁机制。只要用户指定会话的事务隔离级别,数据库就会分析事务中的SQL语句,然后自动为事务操作的数据资源添加适合的锁。此外,数据库还会维护这些锁,当一个资源上的锁数目太多时,自动进行锁升级以提高系统的运行性能,这对用户来说是透明的。
ANSI/ISO SQL92标准定义了4个等级的事务隔离级别,在相同的数据环境下,使用相同的输入,执行相同的工作,根据不同的隔离级别,可能导致不同的结果。不同事务隔离级别能够解决的数据并发问题的能力是不同的。
| 隔离级别 | 脏读 | 不可重复读 | 幻象读 | 第一类丢失更新 | 第二类丢失更新 |
|---|---|---|---|---|---|
| READ UNCOMMITED | 1 | 1 | 1 | 0 | 1 |
| READ COMITED | 0 | 1 | 1 | 0 | 1 |
| REPEATABLE READ | 0 | 0 | 1 | 0 | 0 |
| SERIALIZABLE | 0 | 0 | 0 | 0 | 0 |
闲言碎语
又是一个百无聊赖的周末,同往常一样,蜷缩在狭小的房间里过着与世隔绝的生活。一天没有出门,不知今天的天气如何,是晴天、阴天还是下雨天,一扇摆设似的窗户可以捕捉到天井漏下的天色、迷路的微风和一些房间传出的嘈杂的声音,如此看来,这窗户也倒不是一无是处,至少使得房间不显得那么闷和绝望。
上午窝在被窝里看了《黄金时代》这部电影,之前刚听到这电影名时以为是王小波的《黄金时代》被拍成电影了,后来了解到是讲萧红的平生,当时也没去翻出来看看,昨天看了b站的一个up主讲《呼兰河传》,再次提及了该电影,今天便找来了看看。看完有点儿小压抑,民国四大才女之一的萧红一生也是如此坎坷,在思想陈旧落后保守的年代,萧红逃婚与表哥私奔导致与家庭绝决,被抛弃后又被之前订婚的未婚夫抛弃,然后遇到了生命中最重要的男人萧军,共患难撑过了一段难捱的时光,但最后还是永远的分手了,后嫁给了端木蕻良,赶上日本侵华,颠沛流离,又身患重病,更不幸的是又被医生误诊喉咙有瘤,各种糟糕的事情糅杂在一起加速了萧红的生命走向了终点,年仅31岁。之前看过两遍萧红的《呼兰河传》,喜欢她写的呼兰河小镇的一些琐事,那是描述她童年的回忆,当时没有去了解萧红的一生,只是觉得能写出这样文字的作家很有才,应该也是顺顺当当的,但真没想到是这样的,看了这部电影后再去回味《呼兰河传》,萧红应该是经历了这么多坎坷后对童年生活的怀念和当时那种美好安静生活的思念吧。电影一头爷爷对萧红说,快快长大,长大就好了,但回过头来看,真的是长大就都好了么?这个应该都有体会的吧。
下午整理了下屋子,买了两个收纳箱,把书重新规整了一下,衣服收拾了一下,屋子也都弄了下,但发现还是有点儿乱乱的不知所措,就先这样吧,过不了几天就又乱成一团了。收拾了下心情,纠结了好久终于卸载了b站,以前老借着要在上面看学习视频为由留着,发现学习没学习多少,倒刷小视频上瘾了,实在受不了了就卸载得了,要看视频用电脑看,还能防止在床上葛优躺。之前卸载了知乎,现在没有也不刷了,最多偶尔有想知道的问题在电脑上找一下,今天又卸载了b站,可以省出时间来真正的多看书学习了,还有计划和目标没有安排没有实现,现在正是时候了。
互联网公司部署方案
但凡项目发布,都要考虑两个问题,一个是验证,一个是回滚。
验证就是说,你怎么确定你这次部署成功了?一般来说,要观察每台机器启动后处理请求时的日志,日志是否正常,是否有报错,一般日志正常、没有报错,那么就算是启动成功了,有时候也会让QA/PM做一个线上验证。
那么万一发布失败了呢?此时就得回滚,因为不同的上线是不一样的,有时候你仅仅是对代码做一些微调,大多数时候是针对新需求有上线,加了新的代码/接口,有时候是架构重构,实现机制和技术架构都变了,所以回滚可能也不太一样,比如,如果你是加了一些新的接口,结果上线失败了,此时新接口没人访问,直接代码回滚到旧版本重新部署就行了;如果你是做技术架构升级,此时失败了,可能很多请求已经处理失败,数据丢失,严重的时候会导致公司丢失订单,或者是数据写入了但是都错了,此时可能会采用回滚代码,或者清洗错乱数据的方式来回滚,总之,针对你的发布,你要考虑到失败之后的回滚方案,回滚代码,就得用旧版本的代码,然后重新在各个机器上依次部署,就算是一次回滚了,至于丢失了数据没有,要不要清洗数据,这个看情况来定。
(1)滚动发布
这是最常见的部署模式,一般就是说一个服务/系统都会部署在多台服务器上,部署的时候手动依次进行部署。比如每台服务器上放一个tomcat,每台机器依次停机tomcat,然后把新的代码放进去,再重新启动tomcat,各个服务器都这样做,这就是一种滚动发布。
中小型公司都会做自动化部署,自动化部署用的比较多的就是jenkins,因为jenkins是支持持续集成和持续交付的,简单来说就是你每天都提交代码,他每天都自动跑测试确保代码集成没问题,然后可能隔几天就把一个生产可用的小版本交付到线上。jenkins可以自动在多台机器上部署你的服务/系统,过程其实也是类似的,只不过把手动改成自动罢了。
中大型公司,一般发布系统都是自己研发的,你在上面指定一个服务,指定一个git仓库的代码分支,然后指定一个环境,指定一批机器,发布系统自动到git仓库拉取代码到本地,编译打包,然后在你指定环境的机器上,依次停止当前运行的进程,然后依次重启你新代码的服务进行。
以上这些都是典型的滚动发布。滚动发布的话,风险还是比较大的,因为一旦你用了自动化的滚动发布,那么发布系统会自动把你的所有机器都部署新版本的代码,这个时候中间很有可能会出现问题,导致大规模的异常和损失,所以现在一般中大型公司,都不会贸然用滚动发布模式。
(2)灰度发布
灰度发布就是说,不要上线就滚动全部发布到所有机器,一般就是会部署在比如1台机器上,采用新版本,然后切比如10%的流量过去,观察那10%的流量在1台机器上运行一段时间,比如运行几天时间,观察日志、异常、数据是否一切正常,如果验证发现全部都正常,那么此时就可以全量发布了,全量发布的时候就是采用滚动发布那种模式。
这个好处就是说,你先用10%以内的小流量放到灰度新版本的那台服务器上验证一段时间,感觉没问题了,才会全量部署,这么操作,即使有问题,也就10%以内的请求出现问题,损失不会太大,如果你公司体量特别大,灰度也可以是1%,甚至0.1%的流量。
如果灰度的时候有问题,那么立刻把10%以内的小流量切过去请求老版本代码部署的机器,灰度版本的机器立马就没有流量请求了,这个回滚速度是极快的。
通常灰度验证过后,全量发布都不会有太大的问题,基本上再出问题概率就很小了,所以现在中大型互联网公司一般都是灰度发布模式。
(3)蓝绿部署
蓝绿部署就是说,你得同时准备两个集群,一个集群放新版本代码,一个集群放老版本代码,然后新版本代码的集群准备好了过后,直接线上流量切到新版本集群上,跑一段时间来验证,如果发现有问题,回滚就是立马把流量切回老版本集群,回滚是很快速的。如果新版本集群运行一段时间感觉没问题了,此时就可以把老版本集群给下线了。
那么为什么有灰度发布了还要用蓝绿部署呢?
灰度发布过后,还是要全量部署的,但是有时候,如果涉及到一些新的架构方案,或者是新的接口,10%以内的小流量可能没有办法暴露出线上的高并发问题,所以灰度验证没问题,结果全量部署还是有小概率会失败,此时全量发布用滚动发布的方式,逐步部署过去,很快会引发大规模的失败,此时回滚是很慢的,因为要一台一台逐步回滚。所以说,一般针对那种改动不太大的小版本,比如加一个接口,修改一些代码,修复几个bug,类似这种整体变动不太大的情况,建议使用灰度发布,因为这种一般灰度验证没问题,全量部署也不会有问题。但是如果涉及到那种很大规模的架构重构或者架构升级,比如数据存储架构升级,或者是技术架构整体改造,或者是代码大规模重构,类似这种场景,最好是用蓝绿部署,也就是说,完全部署一个新的集群,然后把较大的流量切过去,比如先切10%,再切50%,最后切到100%,让新集群承载100%的流量跑一段时间。过程中一旦有问题,立马流量全部切回老集群,这个回滚速度比灰度发布的全量部署回滚要快多了,因为仅仅是切流量而已,不需要重新部署。
转正小记
距离4月7号入职已过半年,今天终于要转正了,虽然现在比较佛系,但还是开心一下,毕竟转正后每月工资又多了些,现在就这点儿出息了,哈哈。
今天下午,生平第一次当着十几个人的面演讲ppt,足足讲了40分钟,真是紧张的要死,全程只顾着讲自己的,完全没有节奏,就像小学生背课文一样,哗啦啦一下将准备的东西都倒出来,也管不上听众的感受,自己也是身不由己,从没锻炼过,还有公众讲话恐惧症,不颤音不断片已经够好的了,以后还是要多多锻炼。
今晚可以睡个好觉了,这两天快被这个转正演讲折磨死了,从开始写ppt就一直处于紧张状态,跟打仗备战似的,时不时的进行演练一遍,昨晚重新改ppt加内容再过一遍弄到了1点,躺床上还是翻来覆去睡不着的在想着哪个点要怎样讲,好不容易睡着了梦里还是在和ppt拧巴,早上6点多醒了满脑子都是演讲的内容,脑子里再过一遍,公交地铁上书也没心看,一直在脑海里演练演讲的内容,上班后工作也不在状态也还在一直想着下午要怎么讲,中午吃饭和小伙伴说话都紧张的话都说不利索,吃完饭回来午睡又担心的睡不着手心开始冒汗,下午努力投入到工作中转移注意力,终于在5点开场进行了演讲,第一次第一次,激动、紧张,虽然全都是平时一起工作的同事,大家都很熟悉了,但心理就是这样不设防的塌陷,讲完之后如释重负,没有感动的想哭,只是想手舞足蹈,听着小伙伴们的评论,都是一个劲的夸赞,突然感觉很幸福,觉得自己在这个团队中能将自己的心理问题给治愈,能完善自己的人格缺陷,真真是太好了。最后还是丁总看的透澈,就是自己经历的太少了,踩的坑太少了,而又太脸皮子太薄,以后要多跳坑,有坑就跳,扛过了这波,剩下的就都不是事了。
生活总要有点仪式感,相信今天过后,自己可以朝着自己的展望脚踏实地的奋斗~
Dubbo集成Nacos
deom框架
三个module,一个提供api,一个提供api的实现,一个调用方。工程结构如下图所示。
一、api
提供接口API
public interface ServiceA { String greet(String name); }
二、服务提供方ServiceA
(1)pom.xml配置
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <spring-cloud.version>Greenwich.SR2</spring-cloud.version> </properties> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter</artifactId> <version>2.1.2.RELEASE</version> <exclusions> <exclusion> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-context</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-dubbo</artifactId> <version>2.1.2.RELEASE</version> </dependency> <dependency> <groupId>com.liyyao.demo</groupId> <artifactId>demo-dubbo-nacos-api</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-nacos-discovery</artifactId> <version>2.1.1.RELEASE</version> <exclusions> <exclusion> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-context</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-context</artifactId> <version>2.1.1.RELEASE</version> </dependency> </dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-dependencies</artifactId> <version>2.1.1.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.1.1.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
(2)application.properties配置
spring.application.name=demo-dubbo-nacos-ServiceA dubbo.scan.base-packages=com.liyyao.demo.dubbo.nacos dubbo.protocol.name=dubbo dubbo.protocol.port=20880 dubbo.registry.address=spring-cloud://localhost spring.cloud.nacos.discovery.server-addr=101.133.233.66:8848,101.133.175.55:8848,101.133.172.57:8848
(3)api接口的实现
@Service( version = "1.0.0", interfaceClass = ServiceA.class, cluster = "failfast", loadbalance = "roundrobin" ) public class ServiceAImpl implements ServiceA { public String greet(String name) { return "hello, " + name; } }
(4)启动类
@SpringBootApplication public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } }
三、服务消费方ServiceB
(1)pom.xml配置
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <version>2.1.3.RELEASE</version> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter</artifactId> <version>2.1.2.RELEASE</version> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-dubbo</artifactId> <version>2.1.2.RELEASE</version> </dependency> <dependency> <groupId>com.zhss.demo</groupId> <artifactId>demo-dubbo-nacos-api</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-nacos-discovery</artifactId> <version>2.1.1.RELEASE</version> <exclusions> <exclusion> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-context</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-context</artifactId> <version>2.1.1.RELEASE</version> </dependency> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId> <version>4.5.5</version> </dependency> </dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
(2)application.properties配置
spring.application.name=demo-dubbo-nacos-ServiceB dubbo.cloud.subscribed-services=demo-dubbo-nacos-ServiceA dubbo.scan.base-packages=com.liyyao.demo.dubbo.nacos spring.cloud.nacos.discovery.server-addr=101.133.233.66:8848,101.133.175.55:8848,101.133.172.57:8848
(3)服用ServiceA的方法
@RestController public class TestController { @Reference(version = "1.0.0", interfaceClass = ServiceA.class, cluster = "failfast") private ServiceA serviceA; @GetMapping("/greet") public String greet(String name) { return serviceA.greet(name); } }
(4)启动类
@SpringBootApplication public class Application { public static void main(String[] args) { SpringApplication.run(Application.class, args); } }
四、测试
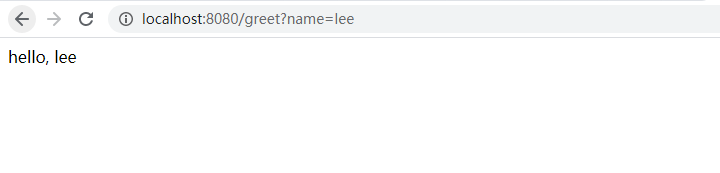
启动成功后,打开浏览器,输入localhost:8080/great?name=lee可访问成功(name的参数输入什么,页面中显示什么)如下图所示。
“反范式”数据库设计之数据冗余架构设计与细节
一、解决什么问题?
(1)数据量大
(2)需要水平切分
(3)一个schema上有多个字段的查询需求举例:订单业务
Order(oid, info_detail)
T(buyer_id, seller_id, oid)
数据量大了怎么办?一个表一个库是存不下的,这个时候往往需要进行水平切分。订单表很容易进行水平切分,根据订单id进行表切分,查询的时候可以根据订单id直接定位到它水平切分到哪个库或者哪个表里面。但是关系表怎么切分呢?有买家id、卖家id,如果通过买家id来水平切分,保证同一个买家id的数据在一个库里或一个表里,根据买家id可以定位到这个买家有多少个订单id,这里如果要用卖家id来查询的话,就需要遍历多个库了;反之如果用卖家id来进行分库分表,同一个卖家的订单关系在一个库或一个表里,此时如果用买家id来查询订单,也需要遍历多个库或多个表。所以不管用买家id还是卖家id来进行水平切分,都有另外一种业务是无法满足的,如果要满足就需要扫描多库,在库的数量非常多数据量非常大的时候,扫描多库的性能是非常非常的低。
二、如何解决?
如果用大学数据库学的范式来解决,几乎是无解的,所以在互联网的某些场景之下,只有逆范式或反范式来设计表结构,进行数据冗余才可以满足在多个业务场景下多个查询条件下的水平切分的需求。
冗余表
Order(oid, info_detail)
T1(buyer_id, seller_id, oid)
T2(seller_id, buyer_id, oid)
三、如何冗余?
(1)服务同步冗余
在进行表数据插入时,同时插入到T1,T2两张表中
优点:1.不复杂; 2.不一致性概率低
缺点:1.因为要插入两张表数据,处理业务时间增加; 2.仍然可能出现不一致(2)服务异步冗余
增加一个消息队列,当插入T1表后,向消息队列中发送一个消息,然后由另外一个服务将数据插入到T2表中
优点:访问一次数据库,与不冗余数据时时间相同
缺点:1.复杂度增加,增加一个MQ; 2.消息发送成功不等于T2插入成功,此时查询T2会查询不到数据,但这个时间比较短,业务上往往是可以接受的; 3.不在一个分布式事务里,会出现数据不一致性(3)线下异步冗余
添加一个bin log,然后调用服务进行T2表的数据插入
优点:两次写操作解耦
缺点:1.有延时,可能在T2中查询不到数据; 2.会出现数据不一致性问题
四、“原子性事务”,正向表和反向表谁先操作?
如果原子性被破坏,不一致出现,谁先做对业务的影响较小,就谁先执行
五、如何保证一致性?
在大数据、高并发、延迟敏感的业务中,并不能实时保证一致性,而是尽可能的发现数据不一致性,然后保证最终一致性。
六、如何保证一致性?
(1)全量数据扫描
写一个离线程序,定时每天检查一次T1和T2表中数据是否一致,不一致的话进行补偿,使数据一致
优点:解耦
缺点:每天都需要大量检测,已经检测过的数据会重复检测,需要耗费的时间长,会导致数据不一致性的时间长(2)增量日志扫
服务插入T1或T2表后向T1日志或T2日志中写一条日志数据,然后写一个离线的程序,对日志进行检测,发现不一致则进行补偿,使数据一致
优点:1.不会重复检测数据; 2.检测周期缩短; 3.线上影响比较低
缺点:时效性还是不高(3)实时消息对检测
增加一个消息队列,插入T1成功后就向消息队列中发送一条消息,插入T2d成功后,就向消息队列中发送一条消息,根据经验,5秒内能收到2条消息,如果未收到消息,则检测数据库数据是否一致
缺点:复杂度高